Testing local LLMs: Qwen 3.5 vs. PowerShell Obfuscation
Recently I finally got to test some local models with Nous Research Hermes-Agent. For the first spin I took these three Qwen 3.5 models:
- qwen3.5-27b-claude-4.6-opus-reasoning-distilled-v2 (Q4_K_M)
- qwen3.5-35b-a3b (Q4_K_M)
- qwen3.5-122b-a10b (Q4_K_S)
Test parameters
- Hardware: All models ran on RTX 5090 + 3080 40GB VRAM + 128GB DDR5 RDIMM RAM (with Threadripper 9960X) setup.
- Context: All models were loaded with 32k context.
- Scenario: All models got the same (gemini generated) set of 6, very lightly obfuscated powershell files (mostly backticks + f-string obfuscation, some nested 👿). With the same prompt:
write a powershell script deobfuscate.py that correctly deobfuscates all test (test[1-6].ps1 in current directory) obfuscated powershell files
Test results
Firstly I will say that I’m positively surprised with all models - this is a massive step up from my previous experiences with local LLMs. While obviously not yet at SOTA levels, the fact that it one-shotted a Python script for PowerShell deobfuscation (simple, but functional!) on the first iteration is impressive. I remember when even getting correct syntax from a local model was a struggle.
So, how did the models do?
1. qwen3.5-27b-claude-4.6-opus-reasoning-distilled-v2 (Q4_K_M)
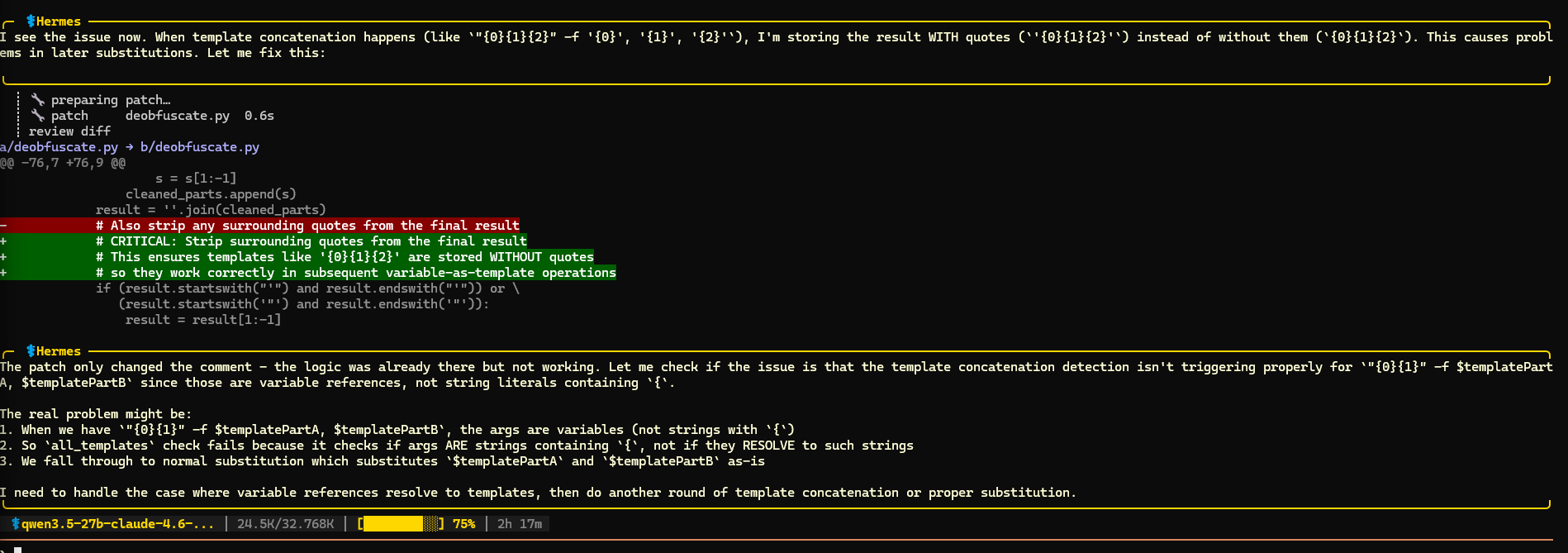
This specifically opus distilled model, got a lot of hype on X recently so I wanted to test it specifically. Note that it’s an improved version 2.
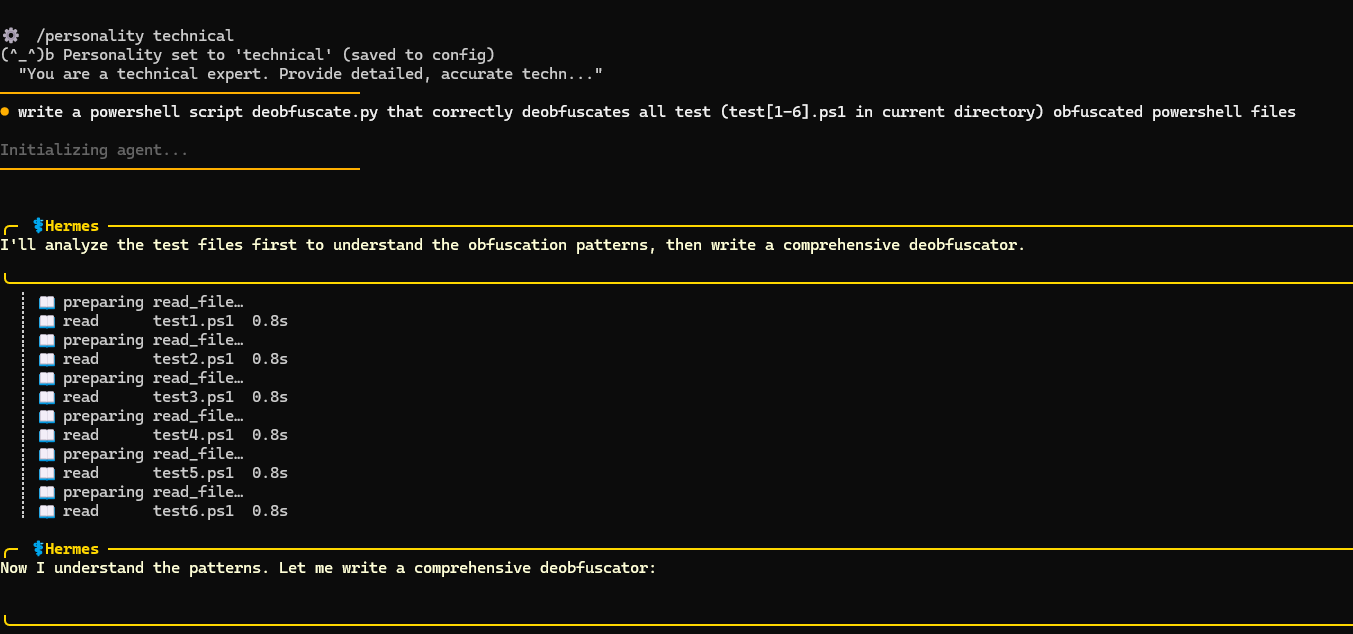
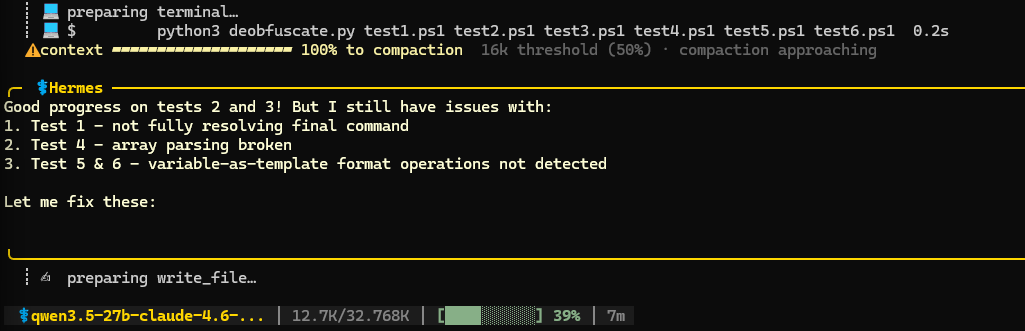
This model didn’t have many issues one-shotting a script to solve the first 3 (easier) tests. It struggled more with tests 4-6. In the end it managed to solve tests 4 and 6, but it got stuck in the loop on test 5. The interesting thing about this test is that there was a typo in the deobfuscated command (thanks Gemini). Get-Procssge instead of Get-Process. Qwen solved it correctly but it thought it’s wrong and it kept trying to improve the script. After 30 minutes I interrupted these futile tries, but overall I’m quite impressed with the stability of this model, coding and reasoning. It could’ve been faster, but this is mostly hardware limitation on my side.
6/6 tests solved. Score: 9/10
I also tested the Q8_0 - higher precision version of this model but didn’t notice much difference. It was slightly slower, and arrived at the correct solution later.
2. qwen3.5-35b-a3b (Q4_K_M)
For some reason this model really struggled with continuous operation, and it usually interrupted execution without any answer after 2-3 steps and it required a small poke to resume work. After a few rounds of this it managed to write a script that partially solved test 1, but I got bored of poking it, and interrupted the experiment. Not sure if this was a fault of the harness, LLM or some settings.
0.5/6 tests solved. Score: 2/10
3. qwen3.5-122b-a10b (Q4_K_S)
I just wanted to try it for the sake of it, but definitely this model is too big for my hardware. It partially offloads to RAM and technically runs, but it’s quite slow 10-15 t/sec and I also got a bunch of timeouts from Hermes talking to the LM Studio server, for some reason. Not sure if this was due to slugginess of the setup, but because of timeouts I couldn;t really test this model. Maybe I will try2-bit version in the future that should fully load to VRAM.
0/6 tests solved. Score: N/A
4. Gemini 3 😁
Just for comparison I ran the same test on Gemini 3. It managed to one-shot a correct solution for all 6 tests in less than 5 minutes. Interestingly it also fell into the same “trap” as qwen3.5-27b where it thought that the solution to test 5 is wrong. Unlike Qwen, after the next iteration it realised it’s actually a correct solution, and reported the correct solution. Of course it’s useless to compare the SOTA model with the 27b local model, but I treat it more as a benchmark.
6/6 tests solved. Score: 10/10
Test summary
The clear winner is qwen3.5-27b (don’t count Gemini) which solved all the tests. I’m genuinely impressed with this distilled model, it deserves all the hype it gets. Although it’s still a bit too slow to be my daily driver and replace Gemini 😁
Future considerations
The main bottleneck right now is the context window. With 32k on my RTX 5090, context compaction kicks in every few calls, which inevitably hits response quality. I could potentially push to 64k, but this would be on the limit of my VRAM.
This is where Google’s TurboQuant provides a possible solution. Early community implementations are showing 3-4x context expansion on the same hardware. While there’s still a hit to generation speed, these are early days. I’m excited to see where this technology goes.